
Author: Subhasish Panigrahi
Optical Character Recognition in a nutshell
Optical Character Recognition (OCR) lets you convert images with text into text documents using automated computer algorithms. Images can be processed individually (.jpg, .png, and .gif files) or in multi-page PDF documents (.pdf). These are some of the types of files suitable for OCR:
- Image or PDF files obtained using flatbed scanners
- Photos taken with digital cameras or mobile phones
Using OCR in Google Drive
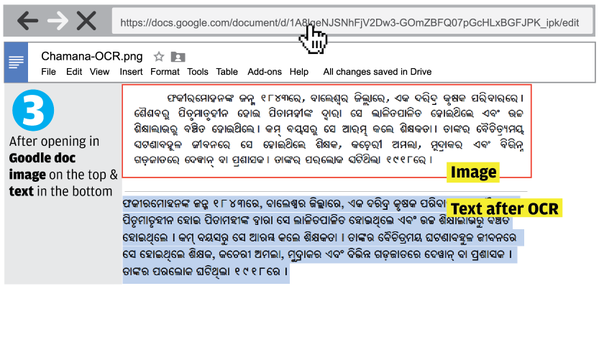
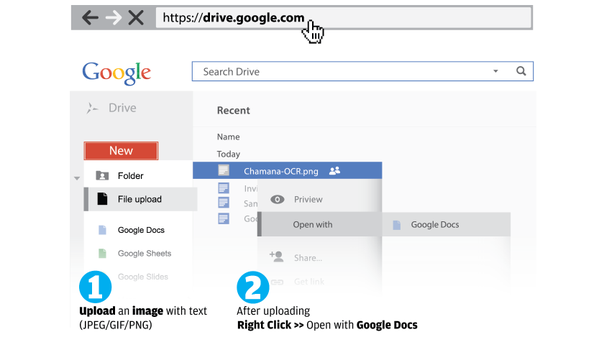
In Google Drive, we take your uploaded images or PDF files, scan the file, and use computer algorithms to convert the file into a Google document.
For best results, the image or PDF files need to meet certain requirements:
- Resolution: High-resolution files work best. As a rule of thumb, we recommend each line of text in the documents to be of at least 10 pixels height.
- Orientation: Only documents oriented with the correct side up are recognized. If you’ve accidentally scanned or captured a document in a different orientation, please use a program to retouch and edit images to rotate them before uploading to Google Drive.
- Languages, fonts and character sets: Our OCR engine supports a large variety of character sets and will detect the language of the document automatically. We recognize left-to-right and right-to-left languages, as well as text written vertically for languages where this is common (Chinese, Japanese, Korean). You’ll get better results if your image includes common fonts such as Arial and Times New Roman.
- Image quality: Sharp images with even lighting and clear contrasts will work best. Motion blur or bad camera focus will decrease the quality of the detected text.